


Two Days Workshop
Secure Federated Machine Learning for Health Informatics
Workshop-Date: Thursday, March, 1, 2018 and Friday, March, 2, 2018
Welcome Reception: Wednesday, February, 28, 2018, 20:00
Venue: SBA-research, Favoritenstrasse 16, 1040 Vienna, Austria
Direction from Airport Vienna: Take OEBB train (runs every 30 Minutes and takes 15 Minutes) to Hauptbahnhof Wien
Direction from Hauptbahnhof to Austria Trendhotel Theresianum: (walk towards Favoritenstrasse 600 m – 8 Minutes)
or underground line U1 (red line) > station Taubstummengasse > exit Floragasse (Workshop venue)
Local Organizers: Andreas HOLZINGER & Peter KIESEBERG
Current as of 25.02.2018 18:20 CET
Workshop Committee:
Prof. Dr. Jan BAUMBACH, Baumbachlab, Experimental Bioinformatics Lab, Technical University Munich, DE
Prof. Dr. Dominik HEIDER, Heiderlab, Department of Mathematics and Computer Science, University of Marburg, DE
Prof. Dr. Andreas HOLZINGER, Holzinger Group HCI-KDD, Inst. for Med. Informatics/Statistics, Medical University Graz, AT
Prof. Dr. Richard ROETTGER, Pract. Computer Science/Bioinformatics Group, University of Southern Denmark, Odense, DK
Prof. Dr. Edgar WEIPPL, SBA-Research Vienna, AT
Increasing privacy concerns in the health domain (e.g. due to new European Data Protection Regulations) require new approaches in AI and machine learning. One problem of the health domain is, that heterogenous data sources are extremely distributed over different locations. Secure storage and sharing of sensitive health data is a big challenge and mostly prohibit open research cross-institutional, even cross-departmental. Current technologies face limitations regarding safety, security, privacy, data protection and ecosystem interoperability. Standard methods, e.g. sending sensitive health data into a cloud for analysis is meanwhile a no-go and not suitable in the future for a number of reasons. The problem is twofold: On the one hand hospitals need a secure platform to store sensitive data, but on the other hand any health research (e.g. cancer research) needs to be openly shared for global research. In the health informatics domain one possible future solution is to in federated machine learning – making use of client-side computing and latest blockchain technologies [1], [2]. The premise is NOT to share any data (!) – but to share the learned representations (features) where a lot of reserach is urgently needed in order to bring novel ideas into daily business. This approach is privacy-by-design.
This workshop brings together experts from diverse areas to pave the way for future collaborations in assessing and reducing cyber risks in hospitals and health care centers to help not only to protect sensitive patient privacy, but at the same time enable international open research on shared representations. The central goal is in improved security of health data, services and infrastructures with no risk of data privacy breaches and increased patient and researcher trust and safety in AI/machine learning approaches in open science.
Keywords: Federated machine learning, client-side computing, privacy aware machine learning, blockchain technologies, health informatics, artificial intelligence, privacy-by-design
Please note that this workshop is by invitation only – if you have interest please contact the organizers.
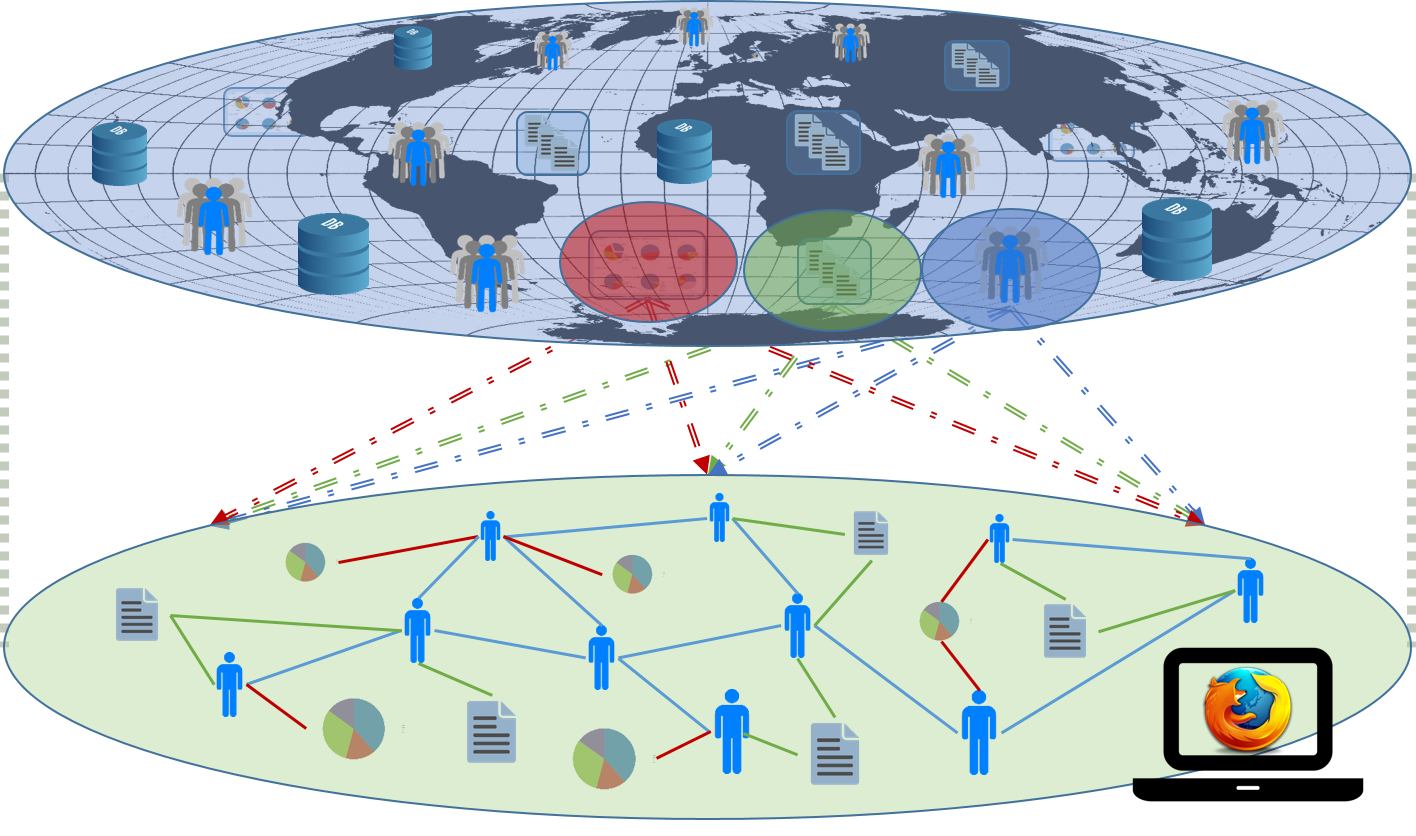
Figure above t aken out of [1]
aken out of [1]
Left: Recent ERCIM special issue on Blockchain Engineering,
with two contributions from SBA-Research
[1] Aljosha Judmayer, Alexei Zamyatin, Nicholas Stifter & Edgar Weippl 2017. Bitcoin-Cryptocurrencies and Alternative Applications. ERCIM NEWS, (110), 10-11.
[2] Nicholas Stifter, Aljosha Judmayer & Edgar Weippl 2017. A Holistic Approach to Smart Contract Security. ERCIM NEWS, (110), 17-18.
https://ercim-news.ercim.eu/en110
[3] Bernd Malle, Nicola Giuliani, Peter Kieseberg & Andreas Holzinger (2017). The More the Merrier – Federated Learning from Local Sphere Recommendations. Machine Learning and Knowledge Extraction, IFIP CD-MAKE, Lecture Notes in Computer Science LNCS 10410 Cham: Springer, pp. 367-374. [preprint] [doi: 10.1007/978-3-319-66808-6_24]
Workshop Program Day 1 (March, 1, 2018)
09:30 From gene panels to federated systems medicine
Jan BAUMBACH, TU Munich, Germany
https://www.baumbachlab.net/head
Abstract:
One major obstacle in current medicine and drug development is inherent in the way we define and approach diseases. Another issues is the general data protection policy (GDPR). Here, we will discuss the diagnostic and prognostic value of (multi-)omics panels in general. We will have a closer look at breast cancer subtyping and treatment outcome, as case example, using gene expression panels – and we will discuss the current “best practice” in the light of critical statistical considerations. We will also discuss why we have <1000 samples available for training despite millions of annual breast cancer samples taken and analyzed worldwide - and how this limits the treatment potential drastically. Afterwards, we will introduce computational approaches for network-based medicine aka. systems medicine. We will discuss novel developments in graph-based machine learning using examples ranging from Huntington’s disease mechanisms via lung cancer drug target discovery back to where we started, i.e. breast cancer subtyping and treatment optimization – but now from a systems medicine point of view. We conclude that systems medicine and modern artificial intelligence open new avenues to shape future medicine. But we also conclude that we are still orders of magnitude behind the potential as we cannot yet overcome GDPR regulations technically without proper federated machine learning approaches tailored to practical medical data mining.
11:00 Challenges and Chances in Federated Unsupervised Learning of Biomedical Data
Richard ROETTGER, University of Southern Denmark, Odense, Denmark
https://imada.sdu.dk/~roettger
Abstract:
Clustering or unsupervised learning is often the first frontier in analyzing and understanding data for subsequent follow-up analyses. For example, only a meaningful patient stratification based on the actual molecular aberrations will enable unraveling the underlying cause of the disease. Using stratifications based on wrong or too wide diagnoses according to the observed phenotype will blur the underlying cause and thus inhibit the subsequent analyses. Especially, when looking at rare diseases or towards precision medicine, this would lead to too small patient groups impeding statistical significance. Overcoming these issues would require joining forces and spread the analysis over several data sources which comes with huge technical, ethical, and legal challenges which slow down or completely prohibit research. In this talk, we will highlight current state-of-the-art unsupervised learning procedures and then call for and lay out potential approaches for federated clustering in order to benefit from large, distributed data sources of various stake holders without the legal and ethical challenges.
13:30 Data Science for MDx Applications: From Academia to Clinic to Industry
Dominik HEIDER, University of Marburg, Germany
Abstract:
The development of computational approaches for predictive modeling of diseases or drug resistance predictions has opened a new era in precision medicine. Clinical decision-support-systems have been designed for assistance in molecular diagnostics (MDx) or companion diagnostics (CDx) to enhance therapeutic success. These systems are typically based on statistical or machine learning models that were build based on clinical or corporate gathered data. The main pitfall of computational models for precision medicine is however the limited access to this data and thus the generalizability to other cohorts. Due to the fact that open data is still an unfulfilled dream in clinical or corporate settings, machine learning models able to work in a federated manner might be an attractive and powerful alternative.
15:00 Utilizing the blockchain in medical applications
Peter Kieseberg, SBA-Research, Vienna, and University of Appplied Sciences St.Pölten, Austria
https://www.sba-research.org/team/seniorstaff/peter-kieseberg
Abstract: Blockchain technology offers a multitude of extremely interesting applications, not only in the area of digital currencies, but also for more complex use cases like smart contracts. Due to its intrinsic capabilities, this technology offers several interesting possible applications in the health informatics sector. On the other hand, the blockchain has unfortunately become a hype topic, thus being added to many applications where it does not actually make sense, as well as people branding other, related technologies as “blockchains”. In this talk an overview is provided on possible relevant and necessary applications for blockchains in the health sector, as well as when not to use the blockchain technology.
17:30 Towards client-based explainable AI
Andreas HOLZINGER, Holzinger Group HCI-KDD, Medical University Graz, Austria
Abstract:
Due to the success of probabilistic models and statistical learning methods, currently cloud based AI demonstrates enormous success in the biomedical domain. Deep learning, trained on big data yet exceed human performance. However, the central problem of such approaches is that they are regarded as “black-box” models and even though we understand the underlying mathematical principles they lack explicit declarative knowledge. This calls for systems enabling to make decisions transparent, understandable and explainable. A huge motivation for Explainable AI are rising legal and privacy aspects. For example, the new European General Data Protection Regulation (GDPR and ISO/IEC 27001) entering into force on May 25th 2018, will make black-box approaches difficult to use. This does not imply a ban on automatic learning approaches or an obligation to explain everything all the time, however, there must be a possibility to make the results re-traceable on request. In this talk I focus on our interactive machine learning (iML) model with a human-in-the-loop in order to make machine decisions transparent, understandable and explainable and to foster the federated learning approach, i.e. avoiding sending sensitive medical data into the cloud for analysis – instead making use of client- side machine learning.
19:00 Federated learning via graph based local sphere recommendations
Bernd Malle, Holzinger Group HCI-KDD Medical University Graz and SBA Research Vienna, Austria
Abstract:
Many of today’s most interesting applications depend on underlying network structures and interactions within or between them, which severely limits their scalability and efficiency, since many exact graph algorithms are polynomial or even exponential in nature. Apart from approximation approaches on a single large graph structure, a possible remedy could lie in defining global structure via local interactions, enabling efficient, scalable, and privacy-aware federated learning on graphs. In this talk I will present the high-level abstract concept of local sphere recommenders in the context of one specific application; I will propose how a global graph structure could emerge and develop from such local interactions and how this paradigm can address the problem of (partly) private information as well as bring the human into the loop. We will round off the talk with a discussion of how local spheres fit into already existing Web-based communication patterns and could thereby democratize innovation potential at the intersection of Machine Learning, Data-driven startups and government-regulated privacy concerns.
Workshop Program Day 2 (March, 2, 2018)
09:00 – 11:00 Discussion Round A: Open Problems and Challenges in Open Science
All participants
Open Science in on top priority of the European Union and part of the Digital Single Market (DSM) initiative of the European Commission. Basically open science describes transitions of the way how research is carried out, how researchers share their data and collaborate and how knowledge is disseminated. Open Science enables more transparency, inclusiveness and networked collaboration. In the long term, it may make science more efficient, reliable and responsive to the grand challenges of our times as well as foster co-creation and Open Innovation. Open Science increases the impact and quality of science and it might also change the assessment of scientific integrity – at the same time increasing patient trust and safety and less risk of privacy breaches caused by cyberattacks and lacking security of health services, data and infrastructures.
11:00 – 13:00 Science Lunch
13:00 – 15:00 Discussion Round B: Towards innovative solutions for assessing and reducing cyber risks
All participants
After a hands-on tutorial on blockchain technologies, particularly blockchain in health informatics, in the last session – in this session the lessons learned will be wrapped up. Summary: Blockchain technologies can help to reduce complexity and enable trustful collaboration for sharing secure information. In machine learning e.g. it is possible not to share data, but to share features (learned representations). In any case it is important to apply client-side machine learning as speed is a very important factor. This is highly relevant particularly for small start-up companies in the pan-European context.
The workshop will be closed with a farewell dinner.
This workshop was organized by the Holzinger Group, HCI-KDD, Institute for Medical Informatics, Statistics and Documentation (IMI), Medical University Graz togehter with Secure Business Austria, SBA-Research Vienna.

