

Current as of: June, 24, 2017 – 20:00 CEST
Machine Learning for Health Informatics
“It is remarkable that a science which began with the consideration of games of chance
should have become the most important object of human knowledge”
Pierre Simon de Laplace, 1812.
2017S, 2.0 h 3.0 ECTS, Type: VU Lecture with Excercises, Language: English
Venue: Vienna University of Technology > Faculty of Informatics
Introduction to this Class: Tuesday, 7th March 2017, 17:30 – 19:30
Seminarraum 127, Gußhausstrasse 25-29, Stiege 1, 3. Stock
(link to TISS)
Lecturers: Andreas HOLZINGER, Holzinger Group HCI-KDD
Rudi FREUND, Theory & Logic Group
Tutors: Marcus BLOICE, Bernd MALLE, Florian ENDEL
You find assignments and tutorial material via Github:
https://github.com/cassinius/GraphiniusJS
https://github.com/cassinius/mlhi-ass2-anonymization
https://github.com/mdbloice/MLDS
https://github.com/FlorianEndel/Probabilistic-Programming-Tutorial
Introduction Paper: HOLZINGER (2016) Machine Learning for Health Informatics. (Students please read this paper first)
Introduction Video: https://www.youtube.com/watch?v=lc2hvuh0FwQ (Students please watch this video first)
Short Description:
Health is increasingly turning into a data driven business. Health industry needs urgently a new kind of graduates!
This graduate course follows a research-based teaching (RBT) approach and discusses experimental methods for combining human intelligence with machine learning to solve problems from health informatics. For practical applications we focus on Python – which is to date the worldwide most used ML-language.
Motto of the Holzinger-Group: Science is to test crazy ideas – Engineering is to put these ideas into Business.
Machine Learning & Health Informatics
is a growing R&D Challenge:
Machine learning (ML) is the most growing field in computer science (Jordan & Mitchell, 2015. Machine learning: Trends, perspectives, and prospects. Science, 349, (6245), 255-260), and it is well accepted that health informatics is amongst the greatest challenges (LeCun, Bengio, & Hinton, 2015. Deep learning. Nature, 521, (7553), 436-444), with Privacy Aware Machine Learning (PAML) as a must!
The future of medicine is in the data and privacy aware machine (un-)learning is no longer a nice to have, but a must.
ML is changing the future of health: Internationally outstanding universities count on the combination of machine learning and health informatics and expand these fields, for example: Carnegie-Mellon University, Harvard, Stanford – just to name a few!
Machine Learning & Health Informatics pose enormous Business Opportunities:
McKinsey: An executive’s guide to machine learning
NY Times: The Race Is On to Control Artificial Intelligence, and Tech’s Future
Economist: Million-dollar babies
Machine Learning & Health Informatics provide Employability for TU Graduates:
“Fei-Fei Li, a Stanford University professor who is an expert in computer vision, said one of her Ph.D. candidates had an offer for a job paying more than $1 million a year, and that was only one of four from big and small companies.”
https://www.mckinsey.com/industries/high-tech/our-insights/an-executives-guide-to-machine-learning
Machine Learning & Health Informatics has Market Opportunity for Spin-offs:
“By 2020, the market for machine learning applications will reach $40 billion, IDC, a market research firm, estimates.
By 2018, IDC predicts, at least 50 percent of developers will include A.I. features in what they create.”
https://www.nytimes.com/2016/03/26/technology/the-race-is-on-to-control-artificial-intelligence-and-techs-future.html?_r=2

Description:
The goal of ML is to develop algorithms which can learn and improve over time and can be used for predictions. In automatic Machine learning (aML), great advances have been made, e.g., in speech recognition, recommender systems, or autonomous vehicles. Automatic approaches, e.g. deep learning, greatly benefit from big data with many training sets. In the health domain, sometimes we are confronted with a small number of data sets or rare events, where aML-approaches suffer of insufficient training samples. Here interactive Machine Learning (iML) may be of help, having its roots in Reinforcement Learning (RL), Preference Learning (PL) and Active Learning (AL). The term iML can be defined as algorithms that can interact with agents and can optimize their learning behaviour through these interactions, where the agents can also be human. This human-in-the-loop can be beneficial in solving computationally hard problems, e.g., subspace clustering, protein folding, or k-anonymization, where human expertise can help to reduce an exponential search space through heuristic selection of samples. Therefore, what would otherwise be an NP-hard problem reduces greatly in complexity through the input and the assistance of a human agent involved in the learning phase. However, although humans are excellent at pattern recognition in dimensions of ≤3; most biomedical data sets are in dimensions much higher than 3, making manual data analysis very hard. Successful application of machine learning in health informatics requires to consider the whole pipeline from data preprocessing to data visualization. Consequently, this course fosters the HCI-KDD approach, which encompasses a synergistic combination of methods from two areas to unravel such challenges: Human-Computer Interaction (HCI) and Knowledge Discovery/Data Mining (KDD), with the goal of supporting human intelligence with machine learning.
Grading:
Machine learning is a highly practical field, consequently this class is a VU: there will be a written exam at the end of the course, and during the course the students will solve related assignments.
Course Organization:
This course is organized in modules containing thematically group topics. The top-level view of concepts, theories, paradigms, models, methods and tools, can be seen in the figure below:
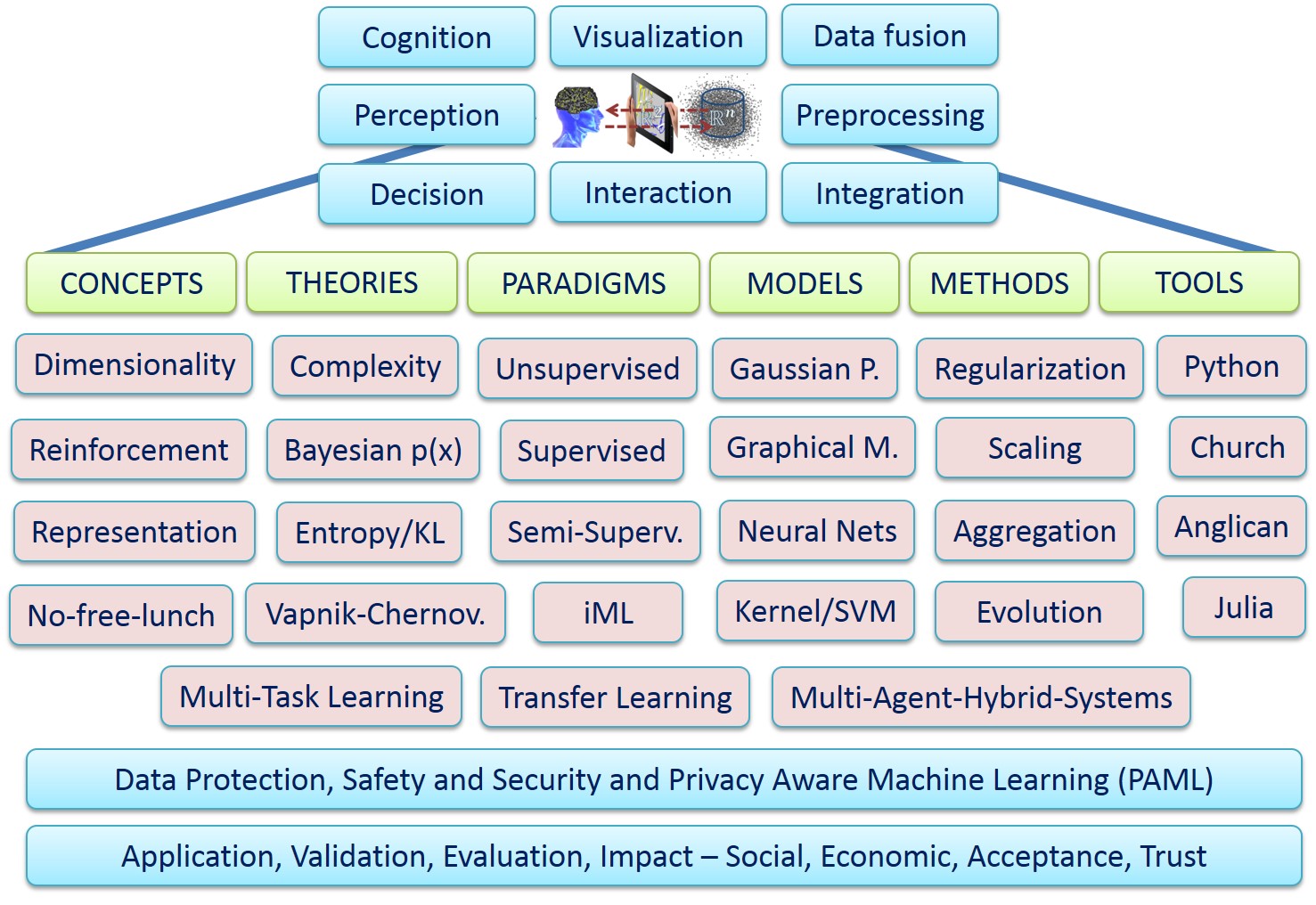
Course Content:
For the successful application of ML in health informatics a comprehensive understanding of the whole HCI-KDD-pipeline, ranging from the physical data ecosystem to the understanding of the end-user in the problem domain is necessary. In the medical world the inclusion of privacy, data protection, safety and security is mandatory.
Differentiation from and bridging to existing courses:
At the TU Vienna are currently two courses on “machine learning”, i.e.
184.702 3VU Machine Learning, in winter term, which deals mainly with principles of supervised and unsupervised ML, including pre-processing and data preparation, as well as evaluation of Learning Systems. ML models discussed may include e.g. Decision Tree Learning, Model Selection, Bayesian Networks, Support Vector Machines, Random Forests, Hidden Markov Models, as well as ensemble methods;
183.605 3VU Machine Learning for Visual Computing, in winter term, which deals mainly with linear models for regression and classification (Perceptron, Linear Basis Function Models, RBF, historical overview), applications in computer vision, neural nets, error functions and optimization (e.g., pseudo-inverse, gradient descent, newton method), model complexity, regularization, model selection, VC dimension, kernel methods: duality, sparsity, Support Vector Machine, principal component analysis and Hebbian rule, canonical correlation analysis, bayesian view of the above models, Bayesian regression, relevance vector machine, clustering und vector quantization (e.g., k-means);
Besides from focusing on health informatics (biological, biomedical, medical, clinical) and health related problems, we will build on and refer to the courses above, to avoid any parallelization, thus will particularly focus on solving problems of health with other ML-approaches (both aML and iML).
Consequently, this course is an addtional benefit for the students of computer science to foster machine learning and to show some examples in the important area of health informatics which is currently a hot topic internationally and opens a lot of future opportunities.
Course Venue: The course takes place in Seminarraum 127, Gußhausstrasse 27-29, Stiege 1, 3. Stock

Lecture 01 – Week 10
Module 01 – Introduction: Machine Learning for health informatics: Challenges and future directions
In the first module we get only a rough overview on the differences between automatic machine learnig and interactive machine learning and discuss a few future challenges as a teaser. MAKE is short for Machine Learning and Knowledge Extraction and this acronym shall emphasize the whole pipeline, where at first we learn from prior data, then extract knowledge in order to generalize and to detect certain patterns in the data and use these to make predictions and help to make decisons under uncertainty – the grand goal of health informatics.
Topic 01: The HCI-KDD approach: Towards an integrative MAKE-pipeline
Topic 02: Understanding Intelligence
Topic 03: The complexity of the application area Health
Topic 04: Probabilistic Information & Gaussian Processes
Topic 05: Automatic Machine Learning (aML)
Topic 06: Interactive Machine Learning (iML)
Topic 07: Active Representation Learning
Topic 08: Multi-Task Learning
Topic 09: Generalization and Transfer Learning
- Lecture slides full size (9.005 KB): 00-Challenges-HOLZINGER-185A83-full-size
- Lecture slides 3 x 3 (3.847 kB): 00-Challenges-HOLZINGER-185A83-3×3
Here some prereading/postreading and video recommendations:
- Holzinger, A. 2016. Interactive Machine Learning for Health Informatics: When do we need the human-in-the-loop? Springer Brain Informatics, 1-13. doi: doi: 10.1007/s40708-016-0042-6
- Dossier: HOLZINGER (2016) Dossier interactive Machine Learning Health Informatics
- Watch the video of Andreas Holzinger: https://youtu.be/lc2hvuh0FwQ
- Watch the video of Google DeepMindHealth: https://youtu.be/teZ2m5oTKwM
- “Medicine is so complex, the challenges are so great … we need everything that we can bring to make our diagnostics more precise, more accurate and our therapeutics more focused on that patient.” Sir Malcolm GRANT, NHS England, in: Machine learning : ROYAL SOCIETY Conference report, Part of the conference series Breakthrough science and technologies Transforming our future with machine learning), https://royalsociety.org/topics-policy/projects/machine-learning
Watch the videos: https://www.youtube.com/playlist?list=PLg7f-TkW11iX3JlGjgbM2s8E1jKSXUTsG
Lecture 02 – Week 11
Module 02 – Health Data Jungle: Selected Topics on Fundamentals of Data and Information Entropy
Topic 01 Data – The underlying physics of data
Topic 02 Data – Biomedical data sources – taxonomy of data
Topic 03 Data – Integration, Mapping and Fusion of data
Topic 04 Information – Bayes and Laplace probabilistic information p(x)
Topic 05 Information Theory – Information Entropy
Topic 06 Information Cross-Entropy and Kullback-Leibler Divergence
Lecture Slides full size (8.901 kB) M01-185A83-HOLZINGER-DATA-SCIENCE-2017-full-size
Lecture Slides 3 x 3 (4.556 kB) M01-185A83-HOLZINGER-DATA-SCIENCE-2017-3×3
Keywords: data, information, probability, entropy, cross-entropy, Kullback-Leibler divergence
Learning Goals:
At the end of this module the students
1) are aware of the problematic of health data and understand the importance of data integration in the life sciences.
2) understand the concept of probabilistic information with a focus on the problem of estimating the parameters of a Gaussian distribution (maximum likelihood problem).
3) recognize the usefulness of the relative entropy, called Kullback–Leibler divergence which is very important, particularly for sparse variational methods between stochastic processes.
Here some prereading/postreading recommendations (alphabetically sorted according to author):
- Banerjee, O., El Ghaoui, L. & D’aspremont, A. 2008. Model selection through sparse maximum likelihood estimation for multivariate gaussian or binary data. The Journal of Machine Learning Research, 9, 485-516, https://www.jmlr.org/papers/v9/banerjee08a.html
- De Boer, P.-T., Kroese, D. P., Mannor, S. & Rubinstein, R. Y. 2005. A tutorial on the cross-entropy method. Annals of operations research, 134, (1), 19-67. doi:10.1007/s10479-005-5724-z
- Galas, D. J., Dewey, T. G., Kunert-Graf, J. & Sakhanenko, N. A. 2017. Expansion of the Kullback-Leibler Divergence, and a new class of information metrics. arXiv:1702.00033.
- Holzinger, A., Dehmer, M. & Jurisica, I. (2014). Knowledge Discovery and interactive Data Mining in Bioinformatics – State-of-the-Art, future challenges and research directions. BMC Bioinformatics, 15, (S6), I1. doi:10.1186/1471-2105-15-S6-I1
- Holzinger, A., Hörtenhuber, M., Mayer, C., Bachler, M., Wassertheurer, S., Pinho, A. & Koslicki, D. (2014). On Entropy-Based Data Mining. In: Holzinger, A. & Jurisica, I. (eds.) Interactive Knowledge Discovery and Data Mining in Biomedical Informatics, Lecture Notes in Computer Science, LNCS 8401. Berlin Heidelberg: Springer, pp. 209-226. doi:10.1007/978-3-662-43968-5_12
Online available: https://pure.tugraz.at/portal/files/3108669/HOLZINGER_Entropy_based_data_mining.pdf - Loshchilov, Ilya, Schoenauer, Marc & Sebag, Michele (2013). KL-based Control of the Learning Schedule for Surrogate Black-Box Optimization. arXiv:1308.2655.
- Matthews, A., Hensman, J., Turner, R. E. & Ghahramani, Z. On sparse variational methods and the Kullback-Leibler divergence between stochastic processes. Proceedings of the Nineteenth International Conference on Artificial Intelligence and Statistics (AISTATS), 2016. JMLR, 231-239 https://www.jmlr.org/proceedings/papers/v51/matthews16.html
Additional reading to foster a deeper understanding of information theory related to the life sciences:
- Manca, Vincenzo (2013). Infobiotics: Information in Biotic Systems. Heidelberg: Springer. (This book is a fascinating journey through the world of discrete biomathematics and a continuation of the 1944 Paper by Erwin Schrödinger: What Is Life? The Physical Aspect of the Living Cell, Dublin, Dublin Institute for Advanced Studies at Trinity College)
Lecture 03 Week 12
Tutorial T1 – Data and Image Augmentation (Tutor: Marcus D. BLOICE) and first assigment
Data augmentation is the artificial generation of data through the expansion of an existing data set. It is a commonly used method in machine learning, and especially in deep learning where large amounts of data are required for training neural networks that have many millions of learning parameters.
In this seminar, we will get an overview of data augmentation in general, and image augmentation in particular. We will introduce the Augmentor software, an open-source Python package written by our group, that can be used to artificially generate image data (based on an original data source) using a stochastic, pipeline-based API.
Last, the structure and API of the Augmentor software will be described. Students who are interested in working on Augmentor can do so for their project deliverable. Students would therefore be expected to extend Augmentor via the project’s GitHib repository by adding functionality to the project, which would then count as their practical assignment for the course.
Learn more about Augmentor here:
https://github.com/mdbloice/Augmentor
Students should prepare for this tutorial by having a working installation of Python with NumPy and other common scientific packages. The easiest way to do this is by installing the Anaconda Python distribution.
From the Anaconda website: “Anaconda is the leading open data science platform powered by Python. The open source version of Anaconda is a high performance distribution of Python and includes over 100 of the most popular Python packages for data science. Additionally, you’ll have access to over 720 packages that can easily be installed with conda, our renowned package, dependency and environment manager, that is included in Anaconda.”
Download and install it here:
https://www.continuum.io/downloads
It does not matter if you install the Python 2.7 or the Python 3.6 version.
Anaconda also includes iPython (an enhanced interactive Python shell), Jupyter (browser-based Python coding notebooks), and Spyder (a Python IDE).
More details can be found in our recent book chapter:
Tutorial Slides (full size, 1,804kB): LV-185A83-Tutorial-ML-Augmentor
Lecture 04 – Week 13
Module 03 – Probabilistic Graphical Models Part 1: From Knowledge Representation to Graph Model Learning
In order to get well prepared for the second tutorial on probabilistic programming, this module provides some basics on graphical models and goes towards methods for Monte Carlo sampling from probability distributions based on Markov Chains (MCMC). This is not only very important, it is awesome, as it is similar as our brain may work. It allows for computing hierachical models having a large number of unknown parameters and also works well for rare event sampling wich is often the case in the health informatics domain. So, we start with reasoning under uncertainty, provide some basics on graphical models and go towards graph model learning. One particular MCMC method is the so-called Metropolis-Hastings algorithm which obtains a sequence of random samples from high-dimensional probability distributions -which we are often challenged in the health domain. The algorithm is among the top 10 most important algorithms and is named after Nicholas METROPOLIS (1915-1999) and Wilfred K. HASTINGS (1930-2016); the former found it in 1953 and the latter generalized it in 1970 (remember: Generalization is a grand goal in science).
Topic 01 Reasoning/Decision Making under uncertainty
Topic 02 Graphs > Networks
Topic 03 Examples of Knowledge Representation in Network Medicine
Topic 04 Graphical Models and Decision Making
Topic 05 Bayes’ Nets
Topic 06 Graphical Model Learning
Topic 07 Probabilistic Programming
Topic 08 Markov Chain Monte Carlo (MCMC)
Topic 09 Example: Metropolis Hastings Algorithm
Lecture Slides full size (7.609 kB) 2-185A83-GRAPHICAL-MODELS-I-HOLZINGER-2017-full-size
Lecture Slides 3 x 3 (3.908 kB) 2-185A83-GRAPHICAL-MODELS-I-HOLZINGER-2017-3×3
Keywords in this lecture: Reasoning under uncertainty, graph extraction, network medicine, metrics and measures, point-cloud data sets, graphical model learning, MCMC, Metropolis-Hastings Algorithm
Reading List (in alphabetical order):
- Bishop, Christopher M (2007) Pattern Recognition and Machine Learning. Heidelberg: Springer [Chapter 8: Graphical Models]
- Chenney, S. & Forsyth, D. A. 2000. Sampling plausible solutions to multi-body constraint problems. Proceedings of the 27th annual conference on Computer graphics and interactive techniques. ACM. 219-228, doi:10.1145/344779.344882.
- Ghahramani, Z. 2015. Probabilistic machine learning and artificial intelligence. Nature, 521, (7553), 452-459, doi:10.1038/nature14541
- Gordon, A. D., Henzinger, T. A., Nori, A. V. & Rajamani, S. K. Probabilistic programming. Proceedings of the on Future of Software Engineering, 2014. ACM, 167-181, doi:10.1145/2593882.2593900
- KOLLER, Daphne & FRIEDMAN, Nir (2009) Probabilistic graphical models: principles and techniques. Cambridge (MA): MIT press.
- Metropolis, N., Rosenbluth, A. W., Rosenbluth, M. N., Teller, A. H. & Teller, E. 1953. Equation of State Calculations by Fast Computing Machines. The Journal of Chemical Physics, 21, (6), 1087-1092, doi:10.1063/1.1699114. (34,123 citations as of 21.03.2017)
- Wainwright, Martin J. & Jordan, Michael I. (2008) Graphical Models, Exponential Families, and Variational Inference. Foundations and Trends in Machine Learning, Vol.1, 1-2, 1-305, doi: 10.1561/2200000001 [Link to pdf]
- Wood, F., Van De Meent, J.-W. & Mansinghka, V. A New Approach to Probabilistic Programming Inference. AISTATS, 2014. 1024-1032.
A hot topic in ML are graph bandits:
- Villar, S. S., Bowden, J. & Wason, J. 2015. Multi-armed Bandit Models for the Optimal Design of Clinical Trials: Benefits and Challenges. Statistical Science, 199-215, doi:10.1214/14-STS504, accesible via: https://arxiv.org/abs/1507.08025
Lecture 05 – Week 14
Tutorial T2 – Probabilistic Programming with Python (Tutor: Florian ENDEL) and second assigment
In this tutorial, we will explore probabilistic programming with the Python framework PyMC3. “Probabilistic programming allows for automatic Bayesian inference on user-defined probabilistic models.” [1]
We will start with an introduction to Markov chain Monte Carlo (MCMC) sampling and its application in Bayesian parameter estimation. Next on, we will dive deeper into the capabilities, workflow and specific utilization of PyMC3. Increasingly complex examples ranging from, e.g., a simple statistical test to a generalized linear model (GLM) will guide us towards Bayesian methodology and the immense power and simplicity of probabilistic programming. Finally, more advanced topics like an alternative to MCMC (e.g. variational inference) and coupling probabilistic programming with Deep Learning will be discussed to highlight the potential of the methodology itself and its implementation in PyMC3. An exercise to help recapitulation of the lessons learned will be provided.
Lecture slides full size (815 kB) 2017-04-04 Probabilistic Programming – Endel
Github: https://github.com/FlorianEndel/Probabilistic-Programming-Tutorial
[1] Salvatier, J., Wiecki, T. V. & Fonnesbeck, C. 2016. Probabilistic programming in Python using PyMC3. PeerJ Computer Science, 2, e55, doi:10.7717/peerj-cs.55
Recommended Video by Thomas Wiecki https://youtu.be/LlzVlqVzeD8
Easter break

Lecture 06 – Week 17
Module 04 – Probabilistic Graphical Models Part 2: From Bayesian Networks to Probabilistic Topic Models
In the last lectures we have seen that our goals are to learn from prior data, to extract knowledge and to generalize – the grand goal is to disentangle the explanatory factors of our data and to understand the data in the context of an application domain – in our case health. In this lecture we will again compare human learning with machine learning and see that in our uncertain environment only probabilistic approaches can be of help. Text (natural language) is of eminent importance in the medical domain and probabilistic topic models can be of great help here.
Topic 01 Probabilistic Decision Making
Topic 02 Probabilistic Topic Models
Topic 03 Knowledge Representation in Network Medicine
Topic 04 Examples for Machine Learning on Graphs
Topic 05 Digression: Geometric Similarity
Topic 06 Graph Measueres (Basics)
Topic 07 Point Clouds from Natural Images
Lecture Slides full size (15.518 kB) 6-185A83-GRAPHICAL-MODELS-II-HOLZINGER-2017
Lecture Slides 3×3 (4.660 kB) 6-185A83-GRAPHICAL-MODELS-II-HOLZINGER-2017-3×3
Keywords in this lecture: Graphical Models and Decision Making, structure learning, factor graphs, function prediction, protein network inference, graph-isomorphism, Bayes’ Nets, machine learning on graphs, subgraph discovery, similarity, correspondence, Gromov-Hausdorff distance, topolopgical spaces in weakly structured data, probabilistic topic models, Latent Dirichlet Allocation LDA.
Blei, D. M., Ng, A. Y. & Jordan, M. I. 2003. Latent Dirichlet allocation. Journal of Machine Learning Research, 3, (4-5), 993-1022.
https://www.jmlr.org/papers/v3/blei03a.html (18.502 citations as of May, 1, 2017)
Murphy, K. P. 2012. Machine learning: a probabilistic perspective, MIT press. Chapter 26 (pp. 907) – Graphical model structure
learning, https://www.cs.ubc.ca/~murphyk/MLbook/
https://fortune.com/2015/10/26/cancer‐clinical‐trial‐belmont‐report/
Lecture 07 – Week 18
Module 05 – Dimensionality Reduction and Subspace Clustering: Example for the Doctor-in-the-Loop
Most of the interesting data in health informatics is in arbitrarily high dimensions, much higher than 3, which is inaccessible to the human. However, many machine learning problems become difficult in high dimensional spaces due to an unwanted effect, known as the curse of dimensionality. Moreover, the number of possible configurations of a data set increases also exponentially, as the number of variables increases. For example in natural language processing, classical n-gram models are very vulnerable to the curse of dimensionality.
Topic 01 Classification vs. Clustering
Topic 02 Feature Engineering: Features are key for learning and understanding
Topic 03 Curse of Dimensionality (GBC-154, 465, 552,
Topic 04 Dimensionaltiy Reduction (PCA, ICA, FA, MDS, LDA, Isomap, LLE, Autoencoders)
Topic 05 Subspace Clustering and Analysis
Topic 06 “What is interesting?” Projection Pursuit
Keywords in this lecture: curse of dimensionality, feature spaces, feature selection, feature extraction, dimensionality reduction (PCA, ICA, FA, MDS, LDA (supervised), Isomap, LLE (laplacian eigenmaps), autoencoders, main focus on: subspaces, subspace clustering;
Lecture Slides (full size, 8.081 kB) 7-185A83-DIMENSIONALITY-REDUCTION-VO-2017
Lecture Slides (3 x 3, 3.586 kB) 7-185A83-DIMENSIONALITY-REDUCTION-VO-2017-3×3
Some prereading/postreading (alphabetically sorted):
- Bengio, S. andBengio, Y. (2000a). Taking onthe curse ofdimensionalityin joint
distributionsusingneuralnetworks.IEEETransactionsonNeuralNetworks,special
issue on DataMiningandKnowledgeDiscovery, (3),550–557. [GBC-709] - Hund, M., Böhm, D., Sturm, W., Sedlmair, M., Schreck, T., Ullrich, T., Keim, D. A., Majnaric, L. & Holzinger, A. 2016. Visual analytics for concept exploration in subspaces of patient groups: Making sense of complex datasets with the Doctor-in-the-loop. Brain Informatics, 1-15: doi: 10.1007/s40708-016-0042-6
- Koch, I. 2014. Analysis of Multivariate and High-Dimensional Data, New York, Cambridge University Press.
- Kriegel, H. P., Kroger, P. & Zimek, A. 2009. Clustering High-Dimensional Data: A Survey on Subspace Clustering, Pattern-Based Clustering, and Correlation Clustering. ACM Transactions on Knowledge Discovery from Data (TKDD), 3, (1), 1-58, doi:10.1145/1497577.1497578.
- Parsons, L., Haque, E. & Liu, H. 2004. Subspace clustering for high dimensional data: a review. SIGKDD Explor. Newsl., 6, (1), 90-105, doi:10.1145/1007730.1007731. [link to pdf]
- Vidal, Rene 2011. Subspace Clustering. IEEE Signal Processing Magazine, 28, (2), 52-68, doi:10.1109/msp.2010.939739. [link to pdf]
A huge critic on machine learning ever since was the uncontrollable “black-box” approach. With iML by bringing a human-into-the-loop, there would be a chance to open this black box to a glass box approach. We will see in the next lectures that a human can be beneficial in helping to solve complex tasks.
Macgregor, J. N. & Chu, Y. 2011. Human performance on the traveling salesman and related problems: A review. The Journal of Problem Solving, 3, (2), 119-150, doi: 10.7771/1932-6246.1094 https://docs.lib.purdue.edu/jps/vol3/iss2/6/
Crossreferences: are given with the topics
Lecture 8 – Week 19
Module 06 – Human learning vs. Machine learning:
Decision Making under Uncertainty and Reinforcement Learning
RL is in principle decision making under uncertainty and has its roots in early psychology (Pavlov, Thorndike, Skinner) and cognitive neuroscience, consequently RL can be seen as a bridge between brains and computers.
Topic 01 What is RL? Why is it relevant?
Topic 02 Decision Making under uncertainty
Topic 03 Roots of RL
Topic 04 Cognitive Science of RL: Human Information Processing
Topic 05 The Anatomy of an RL Agent
Topic 06 Multi-Armed Bandits (MAB)
Topic 07 RL-Applications in health
Slides full size (6.966kB): 8-185A83-HOLZINGER-REINFORCEMENT-LEARNING-2017-full-size
Slides 3×3 (3.461 kB): 8-185A83-HOLZINGER-REINFORCEMENT-LEARNING-2017-3×3
Keywords in this lecture: cognition as probabilistic inference, associative learning, memory, attention, concept learning, reasoning, causal inference, decision making and decision support (highly important for health informatics); single-agent RL, multi-agent RL, n-armed bandits, multi-agent-reinforcement learing (MARL);
- Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidjeland, A. K., Ostrovski, G., Petersen, S., Beattie, C., Sadik, A., Antonoglou, I., King, H., Kumaran, D., Wierstra, D., Legg, S. & Hassabis, D. 2015. Human-level control through deep reinforcement learning. Nature, 518, (7540), 529-533.
https://www.nature.com/nature/journal/v518/n7540/abs/nature14236.html - Niv, Y., Daniel, R., Geana, A., Gershman, S. J., Leong, Y. C., Radulescu, A. & Wilson, R. C. 2015. Reinforcement learning in multidimensional environments relies on attention mechanisms. The Journal of Neuroscience, 35, (21), 8145-8157.
https://www.jneurosci.org/content/35/21/8145.full - Vaidya, A. R. 2015. Neural Mechanisms for Undoing the “Curse of Dimensionality”. The Journal of Neuroscience, 35, (35), 12083-12084. https://www.jneurosci.org/content/35/35/12083.full
- Kaelbling, L. P., Littman, M. L. & Moore, A. W. 1996. Reinforcement learning: A survey. Journal of Artificial Intelligence Research, 4, 237-285. https://www.jair.org/media/301/live-301-1562-jair.pdf
- Sutton, R. S. & Barto, A. G. 1998. Reinforcement learning: An introduction, Cambridge, MIT press.
https://webdocs.cs.ualberta.ca/~sutton/book/the-book.html - Littman, M. L. 2015. Reinforcement learning improves behaviour from evaluative feedback. Nature, 521, (7553), 445-451.
https://www.readcube.com/articles/10.1038%2Fnature14540 - Space Invades (1978): https://www.youtube.com/watch?v=437Ld_rKM2s
- Space Invaders (2015) Deep Mind: https://www.youtube.com/watch?v=iqXKQf2BOSE
- OpenAI Gym: A toolkit for development and comparison of reinforcement learning algorithms
- MMLF – Maja Machine Learning Framework in Python
Lecture 09 – Week 20
Module 07 Evolutionary Computing and Agent Interaction, Part I
Topic 01: Examples of medical applications for Evolutionary Algorithms
Topic 02: Nature-Inspired Computing (Introduction and Overview)
Topic 03: Ant-Colony Optimization (ACO)
Topic 04: Collective Intelligence – Human(s)-in-the-loop
Lecture Slides full size (7,457 kB): 9-185A83-HOLZINGER-EVOLUTIONARY-ALGORITHMS-Multi-Agent-Interaction-2017
Lecture Slides 3 x 3 (3,196 kB): 9-185A83-HOLZINGER-EVOLUTIONARY-ALGORITHMS-Multi-Agent-Interaction-2017-3×3
Keywords in this lecture: computational intelligence (CI), evolutionary computing (EC), medical decison making as a search problem, heuristics vs. analytics, diagnostic reasoning, natural computing, game of life, nature inspiored algorithms, ant colony algorithms, collective intelligence, pheromones, travelling salesman problem (TSP), simulated annealing, function learning, human kernel, problem solving: humans vs. computers, human learning vs. machine learning, human performance;
https://github.com/DEAP/deap
https://pypi.python.org/pypi/deap
Lecture 10 – Week 22
Module 08 – Multi-Agent Interaction with the human-in-the-loop
Topic 00: Reflection
Topic 01: Intelligent Agents
Topic 02: Multi-Agent (Hybrid ) Systems
Topic 03: Application in Health
Topic 04: Medical Decision Making
Topic 05: iML Gamification
Lecture slides full size (4,569 kB): 10-185A83-HOLZINGER-Multi-Agent-Interaction-2017
Keywords in this lecture: Nature-Inspired Computing, NP-hard problems, Ant-Colony Optimization, Human versus Computer, Solving NP-hard problems with the human in the loop, Multi-Agent-Hybrid Systems, Neuroevolution;
Enjoy these Games: https://human-centered.ai/gamification-interactive-machine-learning
and please provide feedback to a.holzinger AT human-centered.ai
Lecture 11 – Week 22
Tutorial T3 – Privacy Aware Machine Learning
This workshop will deal with 3 different but tightly connected aspects of the emerging field of Privacy-aware Machine Learning (PAML) – meaning the application of ML techniques to data sets with artificially decreased information content. Such ‘perturbation’ can either be faced by disruptive outside forces, but more prominently by the user of a system exercising their ‘right to be forgotten’ or prophylactic anonymization on the part of an organization. We have already examined the effects of such perturbation of a standardized dataset on the performance of different classifiers and come to surprising results; the next interesting questions were 1) how do other ML techniques (multi-class classification, prediction, etc.) behave under perturbation, 2) is ML on graph structures more robust under the effects of perturbation, and 3) can interactive Machine Learning (iML) incorporating the Human-in-theloop yield better heuristics for internal cost functions so that information loss in anonymization can be minimized as measured by algorithmic performance. We will examine all of those questions including our experimental setup for iML; students will be able to
conduct a live iML experiment to test the influence of their own human judgment on ML behavior.
Tutorial Slides full size (2.272 kB): Privacy-Aware-Machine-Learning-Tutorial-185-A83-MALLE
Assignment from May, 30, 2017:
Please send your token request directly to Bernd: b.malle AT human-centered.ai
Lecture 12 – Week 24
Module 08 – Evolution Part II: Genetic Algorithms and Neuroevolution: Towards Tumor-Growth Simulation
Topic 00: Reflection
Topic 01: Evolution
Topic 02: Genetic Algorithms
Topic 03: Neuroevolution
Topic 04: Medical Example: Tumor Growth Simulation
Slides full size (4,551kB): 12-185A83-HOLZINGER-Evolutionary-Computing-Neuroevolution-2017
Slides 3×3 (3,828 kB): 12-185A83-HOLZINGER-Evolutionary-Computing-Neuroevolution-2017-3×3
Keywords in this lecture: Evolution, Nature-Inspired Computing, Neuroevolution;
BROWNLEE, Jason 2011. Clever algorithms: nature-inspired programming recipes, Jason Brownlee. Aan excellent open source book > GitHub > https://cleveralgorithms.com
also highly recommendable from Jason BROWNLEE is: https://machinelearningmastery.com/machine-learning-in-python-step-by-step/
https://www.codeproject.com/Articles/644067/Applying-Ant-Colony-Optimization-Algorithms-to-Sol
Scholarpedia Entry Neuroevolution: https://www.scholarpedia.org/article/Neuroevolution
Neuorevolution – a car learns to drive: https://www.youtube.com/watch?v=5lJuEW-5vr8
Neuroevolution – evolving creatures: https://www.youtube.com/watch?v=oiVNxAGC70Q
Genetic Evolution of a wheeled vehicle: https://www.youtube.com/watch?v=uxourrlPlf8
Neuroevolution by Reza Mahjourian: https://github.com/nnrg/opennero/wiki/NeuroEvolution
Neural Networks Research Group at University of Texas: https://nn.cs.utexas.edu/
Lecture 13 – Week 25
Deep Learning Medial: Towards Deep Transfer Learning
Topic 00: Reflection
Topic 01: Fundamentals: From Neural Networks to the limitations of Deep Learning
Topic 02: Remember: representing and dealing with uncertainty
Topic 03: From Bayesian Neural Networks to Gaussian Processes
Topci 04: Stochastic Gradient Descent
Topic 05: Deep Autoencoders
Topic 06: Applications: Biomedical Examples
Topic 07: Future Challenges and Extravaganza Topics
Slides full size (10,226 kB): 13-185A83-HOLZINGER-Deep-Learning-Medical-2017
Slides 3×3 (2,623 kB): 13-185A83-HOLZINGER-Deep-Learning-Medical-2017-3×3
Keywords in this lecture: Deep Learning, Neural Networks, Convolutional Neural Nets
Tensorflow Playground Online: https://playground.tensorflow.org
Tensorflow Playground Offline: https://github.com/tensorflow/playground (requires Node.js)
Learning resources (see also Learning Machine Learning):
Current Research on Assisting Pathologists in Detecting Cancer with Deep Learning:
https://research.googleblog.com/2017/03/assisting-pathologists-in-detecting.html
Detecting Cancer Metastases on Gigapixel Pathology Images
Digital Doctor Nature Video:
Read the full paper: Esteva, A., Kuprel, B., Novoa, R. A., Ko, J., Swetter, S. M., Blau, H. M. & Thrun, S. 2017. Dermatologist-level classification of skin cancer with deep neural networks. Nature, 542, (7639), 115-118, doi:10.1038/nature21056.
https://www.nature.com/nature/journal/v542/n7639/full/nature21056.html
Some libararies, simulators and tools for education and work:
- Understand, experiment and play with Neural Networks: https://playground.tensorflow.org
- You can also loacally install it (needs node.js) https://github.com/tensorflow/playground
- Online Version of: Goodfellow, I., Bengio, Y. & Courville, A. 2016. Deep Learning, Cambridge (MA), MIT Press. https://deeplearningbook.org
- Keras, neural network library in Python, running on top of Deeplearning4j, Tensorflow, CNTK or Theano, by Francois Chollet
https://keras.io - Torch, based on Lua is a scientific computing framework providing deep learning algorithms, see:
https://github.com/torch/torch7 - Theano is a libray for Python for multi-dimensional arrrays (numpy.ndarray) : https://github.com/Theano/
for background see the deeplearning .net and particularly: https://deeplearning.net/software/theano - Caffe is a deep learning framework focusing on speed, e.g it can process 60M images per day (e.g. 1 Peta Byte Images still would need approx. 1 Billion yearsl, note that our planet earth is 4,7 Billion years old.
https://caffe.berkeleyvision.org/
Module – Privacy Aware Machine Learning
Topic 01 Safety (Framework for understanding human error, Swiss Cheese model, risk management, security, safety and technical dependbility)
Topic 02 Privacy (privacy awareness, trade-off between fully anoymized data and non-anonymized data, differential privacy, privacy of medical data, electronic health records, pseudonymization, anonymization)
Topic 03 Privacy aware machine learning (privacy enhancing technologies, the right to be forgotten, EU data protection & privacy act, k-Anonymity, l-Diversity, t-Closeness, social network greedy anonymization (SaNGreeA), perturbation, graph perturbation)
Keywords in this lecture: Privacy, Safety, Security, Data Protection in Machine Learning for Health Informatics
Reading list:
Module – Active Learning and Active Preference Learning: towards interactive Machine Learning
The roots of iML in historical sequence are in reinforcement learning (1950), preference learning (1987), and active learning (1996). Children learn often by query, i.e. they are shown positive examples (“look at this dog”) [1]. The idea behind active learning (AL) is that a ML-algorithm can achieve greater accuracy with fewer training labels, if it is allowed to choose the data from which it learns. An active learner may pose queries, usually in the form of unlabeled data instances to be labeled by an oracle (e.g., a human annotator, for example, see [2]). Active learning is well-motivated in many modern machine learning problems, where unlabeled data may be abundant or easily obtained, but labels are difficult, time-consuming, or expensive to obtain [3]) – this is often the case in the health informatics domain!
Topic 01: Active Learning
Topic 02: Preference Learning
Topic 03: Active Preference Learning
Topic 04: Interactive Learning and Optimization
Topic 05: interactive Machine Learning with the Human-in-the-Loop
Keywords in this lecture: Active Learning, Preference Learning, Active Preference Learning, Interactive Learning and Optimiziation, and interactive machine learning with a human-in-the-loop (iML)
[1] Xu, F. & Tenenbaum, J. B. 2007. Word learning as Bayesian inference. Psychological review, 114, (2), 245-272, doi:10.1037/0033-295X.114.2.245
[2] Yimam, S. M., Biemann, C., Majnaric, L., Šabanović, Š. & Holzinger, A. 2016. An adaptive annotation approach for biomedical entity and relation recognition. Brain Informatics, 3, (3), 157-168, doi:10.1007/s40708-016-0036-4
[3] Settles, B. 2012. Active Learning, San Rafael (CA), Morgan & Claypool, doi:10.2200/S00429ED1V01Y201207AIM018
Module – Multi-Task Learning and Transfer Learning
Keywords in this lecture: Multi-task learning, transfer learning
Topic 01 Inductive Generalization, learning-to-learn (LTL), Hierarchical Bayes
Topic 02 Domain adaptation, Generalized linear mixed models for medical data (Murphy, 2012, p.299)
Topic 03 Multi-Task Feature Learning on multiple Network
Topic 04 Transfer Learning in Psychology (how does a seven-year old child learn to generalize)
Topic 05 Inductive Transfer Learning (Instance Transfer Approach, Model transfer approach)
Topic 06 How to avoid negative transfer?
Reading List:
Tutorial T4 – Machine Learning for Tumor Growth Simulation
In this tutorial you will learn on the application of discrete Multi-Agent Systems on the topic of stochastic simulation of tumor kinetics and key problems for cancer research, tumor growth modeling, cellular potts model, tumor growth visualization and towards using open tumor growth data for machine learning in the international contex.
Keywords in this lecture: tumor growth learning, tumor development, simulation and visualization
Watch the tumor-growth in vivo Video: https://youtu.be/R2Wka7YhhAo
Module E – Machine Learning Algorithm Testing and Evaluation
Keywords in this lecture: performance measures, metrics, error estimation, measures beyond accuracy
Topic 01 Basic Performance measures (hypothesis testing and statistical significance)
Topic 02 Distances and separation measures (Mahalanobis, Kolmogorov-Smirnov, etc.)
Topic 03 Receiver-Operating Characteristics (ROC) and the area under the curve
Topic 04 Error estimation
Reading List:
Drummond, C. & Japkowicz, N. 2010. Warning: statistical benchmarking is addictive. Kicking the habit in machine learning. Journal of Experimental & Theoretical Artificial Intelligence, 22, (1), 67-80.
Japkowicz, N. & Shah, M. 2011. Evaluating learning algorithms: a classification perspective, Cambridge University Press.
Module M – Mathematics for Learning Machine Learning crash course
After you got into Machine Learning you will love to learn the mathematics behind.
The essential mathematics in a nutshell includes: linear algebra, probability & statistics, multidimensional calculus, Measure theory (Maßtheorie), and optimization;
ML Notation pdf, 210kB HOLZINGER-Machine-Learning-Notation
- Dan SIMOVICI & Chabane DJERABA (2014) Mathematical Tools for Data Mining: Set Theory, Partial Orders, Combinatorics, Second Edition. London, Heidelberg, New York, Dordrecht: Springer.
This is a must-have book on every desk, a comprehensive compendium of the maths we need in our daily work, includes topologies and measures in metric spaces. - Keneth H. ROSEN (2013) Discrete Mathematics and its Applications. New York: McGraw-Hill.
This discrete mathematics course book spans a thread through mathematical reasoning, combinatorial analysis, discrete structures, algorithmic thinking and applications & modeling – very recommendable. - Richard O. DUDA, Peter E. HART & David G. STORK (2001) Pattern Classification. New York: John Wiley. This is THE classic work from Bayesian Decision Theory, Nonparametric Techniques, Linear Discriminant Functions and Stochastic Methods with a useful and applicable mathematical foundation. A must-have for any data scientist.
- K.F. RILEY, M.P. HOBSON and S.J. BENCE (2006) Mathematical Methods for Physics and Engineering. Third Edition. Cambridge: Cambridge University Press. A very useful book for every undergraduate student, easy to read. Online available via: https://www.andrew.cmu.edu/~gkesden/book.pdf
Note: The course will be adpated to the students accordingly as the course progresses. Each lecture is preceded by a quiz from the last lecture. The slides will be put online AFTER each lecture – and only those are binding for the final exam.
Short Bio of Lecturer:
Andreas HOLZINGER <expertise> is head of the Holzinger Group, HCI-KDD, Institute for Medical Informatics/Statistics, Medical University Graz, and Associate Professor at the Institute of Interactive Systems and Data Science, Faculty of Computer Science and Biomedical Engineering, Graz University of Technology. His research interests are in supporting human intelligence with machine learning to help to solve complex problems in the health informatics domain. Andreas obtained a Ph.D. in Cognitive Science from Graz University in 1998 and his Habilitation (second Ph.D.) in Computer Science from Graz University of Technology in 2003. Andreas was Visiting Professor in Berlin, Innsbruck, London (2 times), Aachen, and Verona. He was program co-chair of the 14th IEEE International Conference on Machine Learning and Applications of the Association for Machine Learning and Applications (AMLA), and is Associate Editor of the Springer Journal Knowledge and Information Systems (KAIS), Springer Brain Informatics (BRIN), section editor for machine learning at BMC Medical Informatics and Decision Making (MIDM), and founder and leader of the international expert network HCI-KDD. Andreas is member of the IFIG WG 12.9. Computational Intelligence and co-chair of the Cross-Disciplinary IFIP CD-MAKE conference, organizing a session on on privacy aware machine learning (PAML). Since 2003 he has participated in leading positions in 30+ R&D multi-national projects, budget 4+ MEUR, 7800+ citations, h-index =40, g-index=160.
Group Homepage: https://human-centered.ai
Personal Homepage: https://www.aholzinger.at
Youtube Introduction Video: https://youtu.be/lc2hvuh0FwQ
Conference Homepage: https://cd-make.net
Short Bio of Tutors:
Marcus BLOICE is finishing his PhD this year with the application of deep learning on medical images in the Augmentor project. In his tutorial will present the installation and usage of Caffe – see caffe.berkeleyvision.org – a popular deep learning framework developed by the Berkeley Vision and Learning Centre, University of California. It will first discuss how to obtain, compile, and run the Caffe software under Linux on a GPU-equipped workstation. We will then see how, through the use of a mid-range gaming GPU, training times can be reduced by a factor of 20 when compared to a CPU. Lastly, a concrete example of a deep learning task will be presented in the form of a live analysis of a confocal laser scanning microscopy dataset of skin lesion images, by training a model that automatically classifies these images into malignant and benign cases with a high degree of accuracy.
Bernd MALLE is working with Secure Business Austria (SBA) Research and currently pursuing his PhD in machine learning at Graz University of Technology with the Holzinger Group. The amount of patient-related data produced in today’s clinical setting poses many challenges with respect to collection, storage and responsible use. For example, in research and public health care analysis, data must be anonymized before transfer, for which the k-anonymity measure was introduced and successively enhanced by further criteria. As k-anonymity is an NP-hard problem, modern approaches often make use of heuristics based methods. This talk will convey the motivation for anonymization followed by an outline of its criteria, as well as a general overview of methods & algorithmic approaches to tackle the problem. As the resulting data set will be a tradeoff between utility and individual privacy, we need to optimize those measures to individual (subjective) standards. Moreover, the efficacy of an algorithm strongly depends on the background knowledge of a potential attacker as well as the underlying problem domain. I will therefore conclude the session by contemplating an interactive machine learning (iML) approach, pointing out how domain experts might get involved to improve upon current methods.
Florian ENDEL started working as a database developer in the general field of healthcare research in 2007 – after gathering first experiences as high school teacher for two years and working as freelance Web designer, A specific highlight is the development and supervision of “GAP-DRG”, a database holding massive amounts of reimbursement data from the Austrian social insurance system, since 2008. Since then, he was part of several national and international research projects handling, among others, data management, data governance, statistical analytics and secure computing infrastructure. He is currently participating in the EU FP7 project CEPHOS-LINK, the FFG K-Projekt DEXHELPP and still finishing his master’s thesis.
Additional pointers and reading suggestions can be found a the
Learning Machine Learning page
Related Books in Machine Learning:
- MITCHELL, Tom M., 1997. Machine learning, New York: McGraw Hill. (Book Webpages)
Undoubtedly, this is the classic source from the pioneer of ML for getting a perfect first contact with the fascinating field of ML, for undergraduate and graduate students, and for developers and researchers. No previous background in artificial intelligence or statistics is required. - FLACH, Peter, 2012. Machine Learning: The Art and Science of Algorithms that Make Sense of Data. Cambridge: Cambridge University Press. (Book Webpages)
Introductory for advanced undergraduate or graduate students, at the same time aiming at interested academics and professionals with a background in neighbouring disciplines. It includes necessary mathematical details, but emphasizes on how-to. - MURPHY, Kevin, 2012. Machine learning: a probabilistic perspective. Cambridge (MA): MIT Press. (Book Webpages)
This books focuses on probability, which can be applied to any problem involving uncertainty – which is highly the case in medical informatics! This book is suitable for advanced undergraduate or graduate students and needs some mathematical background. - BISHOP, Christopher M., 2006. Pattern Recognition and Machine Learning. New York: Springer-Verlag. (Book Webpages)
This is a classic work and is aimed at advanced students and PhD students, researchers and practitioners, not asuming much mathematical knowledge. - HASTIE, Trevor, TIBSHIRANI, Robert, FRIEDMAN, Jerome, 2009. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. New York: Springer-Verlag (Book Webpages)
This is the classic groundwork from supervised to unsupervised learning, with many applications in medicine, biology, finance, and marketing. For advanced undergraduates and graduates with some mathematical interest.
To get an understanding of the complexity of the health informatics domain:
- Andreas HOLZINGER, 2014. Biomedical Informatics: Discovering Knowledge in Big Data.
New York: Springer. (Book Webpage)
This is a students textbook for undergraduates, and graduate students in health informatics, biomedical engineering, telematics or software engineering with an interest in knowledge discovery. This book fosters an integrated approach, i.e. in the health sciences, a comprehensive and overarching overview of the data science ecosystem and knowledge discovery pipeline is essential. - Gregory A PETSKO & Dagmar RINGE, 2009. Protein Structure and Function (Primers in Biology). Oxford: Oxford University Press (Book Webpage)
This is a comprehensive introduction into the building blocks of life, a beautiful book without ballast. It starts with the consideration of the link between protein sequence and structure, and continues to explore the structural basis of protein functions and how this functions are controlled. - Ingvar EIDHAMMER, Inge JONASSEN, William R TAYLOR, 2004. Protein Bioinformatics: An Algorithmic Approach to Sequence and Structure Analysis. Chicheser: Wiley.
Bioinformatics is the study of biological information and biological systems – such as of the relationships between the sequence, structure and function of genes and proteins. The subject has seen tremendous development in recent years, and there are ever-increasing needs for good understanding of quantitative methods in the study of proteins. This book takes the novel approach of covering both the sequence and structure analysis of proteins and from an algorithmic perspective.
Amongst the many tools (we will concentrate on Python), some useful and popular ones include:
- WEKA. Since 1993, the Waikato Environment for Knowledge Analysis is a very popular open source tool. In 2005 Weka received the SIGKDD Data Mining and Knowledge Discovery Service Award: it is easy to learn and easy to use [WEKA]
- Mathematica. Since 1988 a commercial symbolic mathematical computation system, easy to use [Mathematica]
- MATLAB. Short for MATrix LABoratory, it is a commercial numerical computing environment since 1984, coming with a proprietary programming language by MathWorks, very popular at Universities where it is licensed, awkward for daily practice [Matlab]
- R. Coming from the statistics community it is a very powerful tool implementing the S programming language, used by data scientists and analysts. [The R-Project]
- Python. Currently maybe the most popular scientific language for ML [Python Software Foundation]
An excellent source for learning numerics and science with Python is: https://www.scipy-lectures.org/ - Julia. Since 2012, raising scientific language for technical computing with better performance than Python. IJulia, a collaboration between the Jupyter and Julia, provides a powerful browser-based graphical notebook interface to Julia. [julialang.org]
Please have a look at: What tools do people generally use to solve problems?
Recommendable reading on tools include:
- Wes McKINNEY (2012) Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPython. Beijing et al.: O’Reilly.
This is a practical introduction from the author of the Pandas library. [Google-Books] - Ivo BALBAERT (2015) Getting Started with Julia Programming. Birmingham: Packt Publishing.
A good start for the Julia language and more focused on scientific computing projects, it is assumed that you already know about a high-level dynamic language such as Python. [Google-Books]
International Courses on Machine Learning:
- Carnegie Mellon University > Machine Learning Course 10-701 2015
by Eric XING (expertise) and Ziv-Bar JOSEPH (expertise)
https://www.cs.cmu.edu/~epxing/Class/10701/lecture.html - Carnegie Mellon University > Machine Learning Course 10-701/15-781 2011
by Tom MITCHELL (expertise)
https://www.cs.cmu.edu/~tom/10701_sp11/ - Carnegie Mellon University > Machine Learning Course 10-601 2015
by Maria-Florina BALCAN (expertise) and Tom MITCHELL (expertise)
https://www.cs.cmu.edu/~ninamf/courses/601sp15/ - Carnegie Mellon University > Machine Learning Course 10-701 2013
by Alex SMOLA (expertise)
https://alex.smola.org/teaching/cmu2013-10-701/index.html - Carnegie Mellon University > Machine Learnigng Course 10601b 2015
by Seyoung KIMhttps://www.cs.cmu.edu/~10601b/ - Cornell University > Machine Learning CS 4780/5780 2014
by Thorsten JOACHIMS (expertise)
https://www.cs.cornell.edu/courses/cs4780/2014fa/ - Cornell University > General Machine Learning, Knowledge Extraction
and Data Science courses
https://machinelearning.cis.cornell.edu/pages/courses.php - Oxford > Department of Computer Science > Machine Learning: 2014-2015
by Nando de FREITAS (expertise)
https://www.cs.ox.ac.uk/teaching/courses/2014-2015/ml/index.html
Conferences, Workshops and Courses related to Machine Learning and with health among the application topics
- CD-MAKE – Cross Domain Conference for MAchine Learning and Knowledge Extraction
https://cd-make.net/
- NIPS 2015, Workshop on Machine Learning in Healthcare, Montreal (CA)
https://sites.google.com/site/nipsmlhc15/home - IET Conference on Machine Learning in Healthcare, Balliol College, Oxford (UK)
https://www.theiet.org/events/2015/220928.cfm - Unsing Machine Learning in Health Research, UCL London (UK)
https://www.ucl.ac.uk/farr-short-courses/scfarr17
Pointers:
A) Students with a GENERAL interest in machine learning should definitely browse these sources:
- TALKING MACHINES – Human conversation about machine learning by Katherine GORMAN and Ryan P. ADAMS <expertise>
excellent audio material – 24 episodes in 2015 and three new episodes in season two 2016 (as of 14.02.2016) - This Week in Machine Learning and Artificial Intelligence Podcast
https://twimlai.com - Data Skeptic – Data science, statistics, machine learning, artificial intelligence, and scientific skepticism
https://dataskeptic.com - VIDEOLECTURES.NET Machine learning talks (3,580 items up to 31.01.2017) ML is grouped into subtopics
and displayed as map – highly recommendable - TUTORIALS ON TOPICS IN MACHINE LEARNING by Bob Fisher from the University of Edinburgh, UK
B) Students with a SPECIFIC interest in interactive machine learning should have a look at:
https://human-centered.ai/lv-706-315-interactive-machine-learning/