
Explainable AI Methods – A brief overview (open access)
open access paper available – free to the international research community


open access paper available – free to the international research community

This basic research project will contribute novel results, algorithms and tools to the international ai and machine learning community

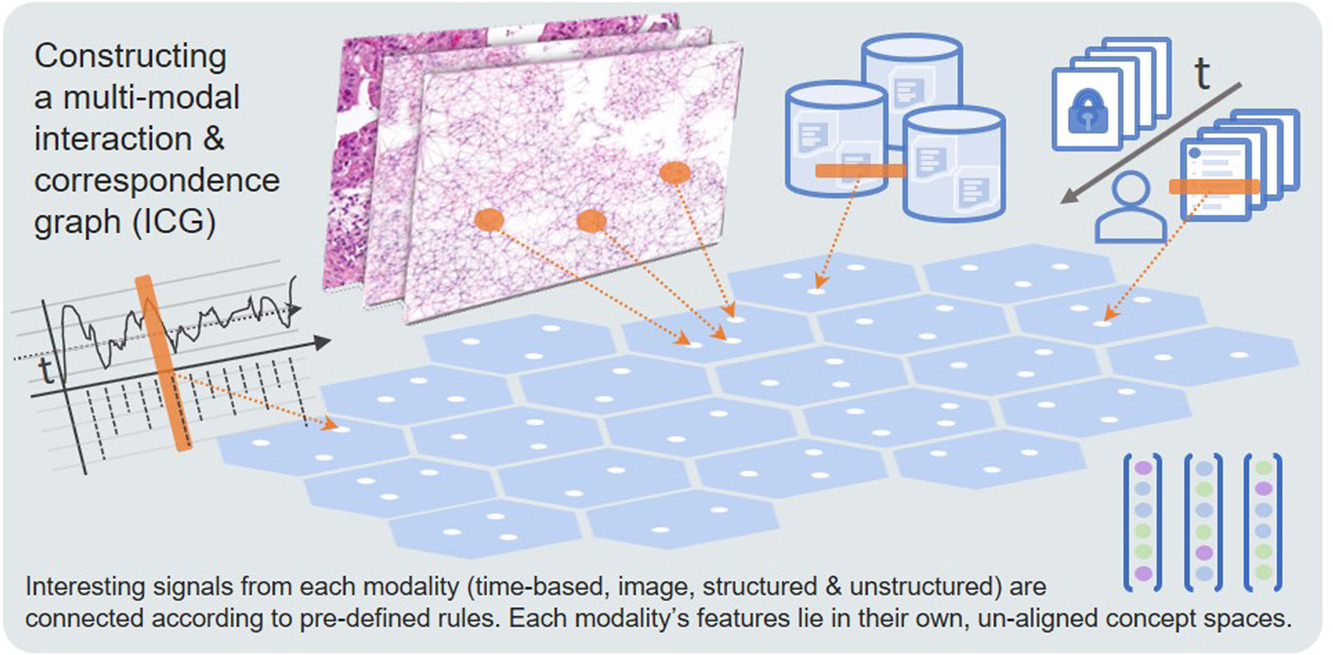
Our paper Towards multi-modal causability with Graph Neural Networks enabling information fusion for explainable AI has been published on 27 January 2021 in the Journal Information Fusion, Q1, IF=13,669, rank 2/137 in the field of Computer Science, Artificial Intelligence:
https://doi.org/10.1016/j.inffus.2021.01.008
We are grateful for the valuable comments of the anonymous reviewers. Parts of this work have received funding from the EU Project FeatureCloud. The FeatureCloud project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No. 826078. This publication reflects only the author’s view and the European Commission is not responsible for any use that may be made of the information it contains. Parts of this work have been funded by the Austrian Science Fund (FWF) , Project: P-32554 “explainable Artificial Intelligence”.

In this paper we introduce our System Causability Scale to measure the quality of explanations. It is based on our notion of Causability (Holzinger et al. in Wiley Interdiscip Rev Data Min Knowl Discov 9(4), 2019) combined with concepts adapted from a widely-accepted usability scale.
The Journal Information Fusion made it to rank 2 out of 136 journals in the field of Artificial Intelligence, congrats to Francisco Herrera, this is excellent for our special issue on rAI – which goes beyond xAI towards accountability, privacy, safety and security.
In our recent highly cited paper we define the notion of causability, which is different from explainability in that causability is a property of a person, while explainability is a property of a system!

There are many different machine learning algorithms for a certain problem, but which one to chose for solving a practical problem? The comparison of learning algorithms is very difficult and is highly dependent of the quality of the data!


“It’s time for AI to move out its adolescent, game-playing phase and take seriously the notions of quality and reliability.”
There is an interesting commentary with interviews by Don MONROE in the recent Communications of the ACM, November 2018, Volume 61, Number 11, Pages 11-13, doi:
Artificial Intelligence (AI) systems are taking over a vast array of tasks that previously depended on human expertise and judgment (only). Often, however, the “reasoning” behind their actions is unclear, and can produce surprising errors or reinforce biased processes. One way to address this issue is to make AI “explainable” to humans—for example, designers who can improve it or let users better know when to trust it. Although the best styles of explanation for different purposes are still being studied, they will profoundly shape how future AI is used.
Some explainable AI, or XAI, has long been familiar, as part of online recommender systems: book purchasers or movie viewers see suggestions for additional selections described as having certain similar attributes, or being chosen by similar users. The stakes are low, however, and occasional misfires are easily ignored, with or without these explanations.
“Considering the internal complexity of modern AI, it may seem unreasonable to hope for a human-scale explanation of its decision-making rationale”.
Read the full article here:
https://cacm.acm.org/magazines/2018/11/232193-ai-explain-yourself/fulltext
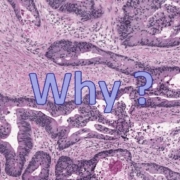
Cartoon no. 1838 from the xkcd [1] Web comic by Randall MUNROE [2] describes in a brilliant sarcastic way the state of the art in AI/machine learning today and shows us the current main problem directly. Of course you will always get results from one of your machine learning models. Just fill in your data and you will get results – any results. That’s easy. The main question remains open: “What if the results are wrong?” The central problem is to know at all that my results are wrong and to what degree. Do you know your error? Or do you just believe what you get? This can be ignored in some areas, desired in other areas, but in a safety critical domain, e.g. in the medical area, this is crucial [3]. Here also the interactive machine learning approach can help to compensate or lower the generalization error through human intuition [4].

[1] https://xkcd.com
[2] https://en.wikipedia.org/wiki/Randall_Munroe
[3] Andreas Holzinger, Chris Biemann, Constantinos S. Pattichis & Douglas B. Kell 2017. What do we need to build explainable AI systems for the medical domain? arXiv:1712.09923. online available: https://arxiv.org/abs/1712.09923v1
[4] Andreas Holzinger 2016. Interactive Machine Learning for Health Informatics: When do we need the human-in-the-loop? Brain Informatics, 3, (2), 119-131, doi:10.1007/s40708-016-0042-6. online available, see:
https://human-centered.ai/2018/01/29/iml-human-loop-mentioned-among-10-coolest-applications-machine-learning
There is also a discussion on the image above:
https://www.explainxkcd.com/wiki/index.php/1838:_Machine_Learning